RNN(Recurrent Neural Network)
RNN은 재귀 호출(Recursive call)을 통해 자연어 처리에 특화되어 있다. 정확히는 동음 이의어를 처리하기 위해 앞뒤 문맥을 살피는 역할로 쓰인다. 만약 자연어를 원 핫 인코딩(One-Hot Encoding)으로 처리한다면 몇가지 문제가 생길 수 있다. 바로 동음 이의어와 유사 단어에 대한 처리이다. 여기서 원 핫 코딩이란 다중 분류에서 사용되는 것으로 분류해야할 대상이 여러개인 경우 각각의 종류를 벡터화 하는 과정을 원 핫 코딩이라고 한다. 아래 그림은 원 핫 인코딩을 이해하기 쉽게 표현한 것이다.

위와 같이 다중 분류 문제의 경우 원 핫 코딩을 통해 분류를 나누고 유사한 특징에 따라 예측을 하게된다. 예를 들어 강아지의 이미지를 모델에게 주면 모델은 해당 이미지에서 특징 추출 후 학습에서 강아지와 관련된 특징이 많이 발견 될 것이다. 그럼 위의 그래프에서 y축(개)에 가깝게 점이 찍히게 되고 최종적으로 다른 분류 대상에 비해 비교적 가까히 있는 '개'로 판단하게 된다. 이렇게 분류가 확실한 경우 원 핫 인코딩만을 사용해도 되지만 자연어의 경우 수 많은 동음이의어와 유사 단어가 존재한다. 예를 들어 '사과'라는 단어에 과일의 '사과'와 미안함을 표하는 '사과'로 나눠지는 경우이다. 이 경우에 '사과'라는 단어를 원 핫 인코딩으로 만들어버리면 다른 의미의 단어이지만 벡터에서는 하나의 의미로 결정된다.
따라서 자연어의 경우 앞 뒤 문맥을 파악하고 문장에서 핵심이 되는 단어를 골라내어 올바른 해석을 할 수 있게 처리를 해줘야 한다. 해당 과정에 특화되어있는 것이 RNN이다. 주의할 점은 원 핫 인코딩만 사용할 시 문제가 발생하는 것이지 RNN에서 원 핫 인코딩을 사용하지 않는 것은 아니다. 자연어 처리 순서 크게 나누면 다음과 같다.

위 그림과 같이 원 핫 인코딩을 필요로 한다. 다음 과정으로 임베딩(Embeding)이 있는데 해당 과정은 유사어를 처리하기 위해 사용된다. 임베딩은 비슷한 단어 3개가 있다고 가정할 때 해당 단어들을 같은 벡터 방향으로 묶어버리는 것이다. 예를 들어 '좋아한다', '사랑한다', '애정한다', '친애한다' 등은 단어 자체는 다르지만 의미 자체는 비슷한 의미이다. 이러한 단어의 경우 하나의 벡터로 묶어주는 과정으로 의미를 하나로 합치고 벡터의 길이가 과도하게 길어지는 것을 해결할 수 있다. 여기서 벡터의 길이가 과도하게 길어진다는 것은 본 포스팅 처음에 벡터화에 대한 이미지를 그래프로 표현했지만 코드로 넘길 시 배열로 전달될 것이다. 즉, 3가지의 벡터가 있다고 할 때 코드에서는 [[1, 0, 0], [0, 1, 0], [0, 0, 1]] 이런식으로 표현된다. 만약 수 많은 자연어를 원 핫 인코딩으로 벡터화 한다면 길이가 과도하게 늘어날 것이다. 임베딩을 위해서는 단어들에 대해 사람이 직접 묶어줘야할 필요가 있는데 이 과정을 조금이나마 덜어줄 수 있는 방법은 구글에서 제공하는 임베딩 벡터를 사용하면 된다. 'word 2 vec'을 사용하면 임베딩을 할 수 있게 미리 나눠둔 단어들이 포함되어 있다.
이후 임베딩 과정을 거친 후 문제인 동음이의어를 처리를 RNN에서 담당한다. RNN은 여러 개의 데이터가 순서대로 입력되었을 때, 앞서 입력받은 데이터를 잠시 기억해 두는 방법을 사용한다. 즉, 이어진 문장의 단어들을 기억하여 문장 전체를 파악할 수 있는 것이다. 단어를 기억하는 과정에서 기억된 데이터가 얼마나 중요한지 별도의 가중치를 줘서 다음 단어로 넘어가는 형식이다. 이때, 실행되는 형태가 마치 다음 층으로 넘어가기 전 같은 층을 여러 번 맴도는 것처럼 보여서 RNN(순환 신경망)이라는 이름을 갖게 되었다. 순환 신경망을 간단히 그림으로 표현하면 다음과 같다.

위의 그림과 같이 다수의 입력으로 하나의 출력을 할 수도 있지만 반대로 하나의 입력으로 다수의 출력 또한 할 수 있다. 이 점이 RNN의 장점이다. 예를 들어 꼭 자연어가 아니더라도 아래와 같은 이미지를 넣어줬을 때 출력값으로 [고양이, 쇼핑백, 의자] 이런식으로 여러 결과를 출력할 수도 있는 것이다.

또한 다수 입력 다수 출력도 가능하다. 해당 경우는 번역기에서 사용되는 경우로 입력 받은 단어들에 대해 각각을 번역한 단어들을 출력하는 것이다. 물론 번역기에서는 단어를 번역 후 해당 나라의 문법에 맞게 재조립하는 과정이 포함될 것이다.

RNN의 한계와 LSTM(Long Short Term Memory)
RNN은 바로 직전의 단어를 기억하며 다음 단어의 처리에 반영하기에는 적합하다. 하지만, 만약 최초의 단어가 마지막 순간에 영향을 미쳐야할 경우라면 반영되기 힘들어진다. 이유는 문장이 길어질수록 나눠지는 단어의 수가 많아지고 단어를 순환하며 이어갈수록 처음 단어의 영향력이 점점 낮아지기 때문이다. 예를 들어 "집에 가는중인데 날씨도 흐리고 기분도 별로 안좋네, 가서 뭐먹지?"라는 문장이 있을 때 결정적인 의미는 '집에 가서 뭐먹지?'인데 중간에 불필요한 단어들로 인해 '집'이라는 키워드가 '가서 뭐먹지?'에 미치는 영향력이 작아진다.
위와 같이 문장이 길어질 경우 올바른 의미를 파악하기 위해 RNN에 대한 많은 연구가 진행되었고 이 중 LSTM(Long Short Term Memory) 방법을 함께 사용하는 기법이 현재 가장 널리 사용되고 있다. 이번 포스팅의 초반부에 자연어 처리 과정 이미지의 마지막 부분에 있던 LSTM이다. LSTM은 한 층 안에서 반복을 많이 해야 하는 RNN의 특성 상 일반 신경망 보다 기울기 소실 문제가 더 많이 발생하고 이를 해결하기 어렵다는 단점을 보완한 방법이다. 즉, 반복되기 직전에 다음 층으로 기억된 값을 다음 층으로 넘길지 안넘길지 관리하는 단계를 하나 더 추가하는 것이다. 해당 과정을 단어와 단어사이에 반복 수행하며 불필요한 단어의 경우 걸러내고 필요한 단어만 다음층으로 올려보내며 최종적으로 긴 문장도 필요한 키워드만으로 이루어지게 된다. LSTM이 적용된 RNN의 과정은 다음 그림과 같다.
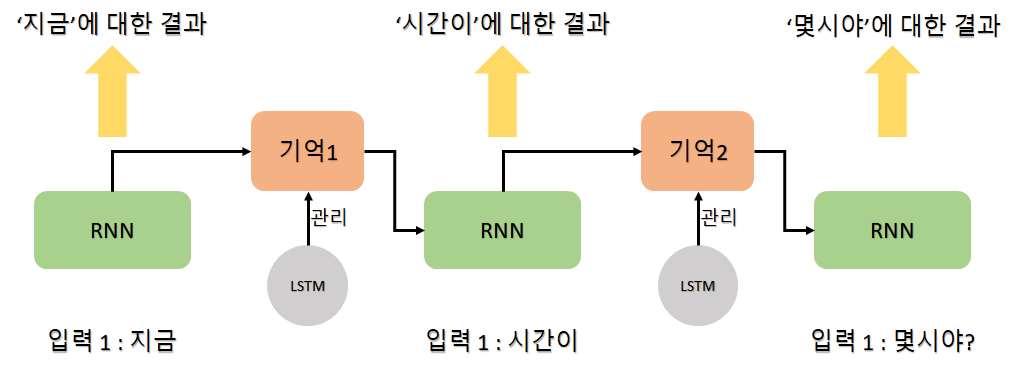
위의 그림과 같이 LSTM은 전달되는 정보에 대해 중요도를 체크하는 단계를 추가하므로써 중요한 정보를 마지막까지 가져갈 수 있다.
임베딩(Embedding) 모델링
시작하기 앞서서 딥러닝은 학습을 할 때 대용량의 데이터를 필요로 한다. 다행히 자연어의 경우 일상생활에서도 지속적으로 생성되는 데이터로, 대용량의 데이터를 수집하기 용이하다. 때문에 Apple사의 시리, Google의 어시스턴트, Amazon의 알렉사 등의 인공지능 비서는 지속적으로 데이터를 수집하여 더욱 자연어를 잘 인식하고 이해할 수 있는 방향으로 성장하는 것이다.
자연어 학습을 위해서는 우선 텍스트를 잘게 나눌 필요가 있다. 입력할 텍스트가 준비되면 이를 단어별, 문장별, 형태소별로 구분할 수 있다. 이렇게 작게 나누어진 하나의 단위를 토큰(Token)이라고 한다. 입력된 텍스트를 잘게 나누는 과정을 토큰화(Tokenization)라고 한다. 토큰화는 케라스에서 제공하는 'text_to_word_sequence()' 함수를 사용하면 문장을 단어 단위로 구분할 수 있게 해준다.
from tensorflow.keras.preprocessing.text import text_to_word_sequence
text = '오늘은 날씨가 엄청 좋았다'
result = text_to_word_sequence(text)
print(result)
코드를 실행하면 다음과 같은 결과를 볼 수 있다.

토큰화를 진행한 다음 해당 토큰들을 이용하여 여러 작업들을 할 수 있는데, 그 중 각 단어가 몇 번이나 문장에 등장하는지를 해볼 것이다. 해당 작업은 Bag-of-words를 사용하면 할 수 있다. Bag-of-words는 단어를 각 가방에 넣고 가방에 몇 개의 단어가 들어있는지 세는 기법이다. 테스트를 위해 'text' 변수의 값을 바꿔준다.
from tensorflow.keras.preprocessing.text import Tokenizer
text = ['먼저 텍스트의 각 단어를 나누어 토큰화 한다.',
'텍스트의 단어로 토큰화 해야 딥러닝에서 인식된다.',
'토큰화한 결과는 딥러닝에서 사용할 수 있다.']
token = Tokenizer()
token.fit_on_texts(text)
print(token.word_counts)
print(token.document_count)
print(token.word_docs)
print(token.word_index)
실행결과는 다음과 같다.

이와 같은 작업으로 자연어에 대한 전처리를 수행할 수 있다.
본격적으로 자연어 처리에 들어가기 위해 단어를 원 핫 인코딩을 해준다. 자연어 역시 각 단어별로 분류가 필요하기 때문에 원 핫 인코딩을 진행한다. 이후 앞서 설명한 것처럼 임베딩, RNN, LSTM의 작업으로 다듬어주는 것이다. 실습은 영화 리뷰를 남겼다고 가정하고 진행한다.
from tensorflow.keras.preprocessing.text import Tokenizer
import numpy as np
docs = ['너무 재밌네요', '최고예요', '참 잘 만든 영화에요', '추천하고 싶은 영화입니다', \
'한번 더 보고 싶네요', '글쎄요', '별로예요', '생각보다 지루하네요', '연기가 어색해요', '재미없어요']
docs_class = np.array([1,1,1,1,1,0,0,0,0,0])
token = Tokenizer()
token.fit_on_texts(docs)
print(token.word_counts)
실행 결과는 다음과 같다.

docs_class는 각각의 리뷰에 대해 긍정과 부정을 나눈 것이다. 처음 5개는 긍정의 리뷰, 뒤에 5개는 부정의 리뷰로 판단한 것이다. 즉, 학습을 위한 데이터이다.
다음으로 토큰에 지정된 인덱스로 새로운 배열을 생성한다.
x = token.text_to_sequences(docs)
print(x)
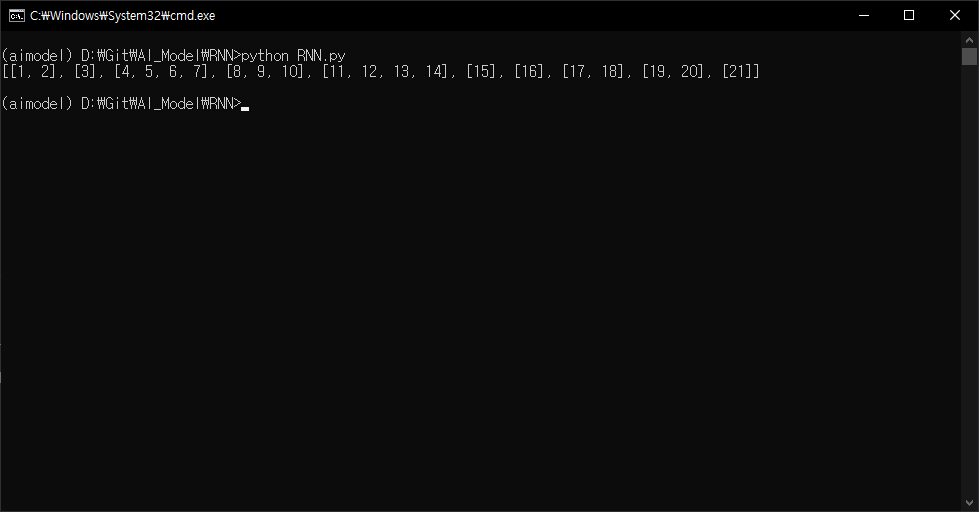
출력에서 알 수 있듯이 각각의 감성평에 따라 배열의 길이가 다르다. 학습을 위해서는 모두 동일하게 길이를 맞춰줄 필요가 있다. 즉, 패딩(Padding)이 필요하다. 패딩은 블록 암호에서도 자주 사용되는 것으로 데이터의 길이를 일정하게 맞추기 위해 길이가 부족한 데이터에 임의의 패딩 값을 넣어 모두 동일한 길이로 맞춰주는 것이다. 출력값으로 보아 가장 긴 문장은 최대 4개의 배열로 이루어져 있기 때문에 모든 값을 4개로 맞춰준다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
padding_x = pad_sequences(x, 4)
print(padding_x)

패딩 후 모든 문장의 길이가 같아진 것을 확인할 수 있다. 이제 텍스트를 읽고 긍정, 부정을 예측하는 학습 모델을 설정한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Embedding
word_size = len(token.word_index) + 1
model = Sequential()
model.add(Embedding(word_size, 8, input_length=4))
model.add(Flatten())
model.add(Dense(1, activation="sigmoid"))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(padding_x, docs_class, epoches=20)
print("\n Accuracy: %.4f" % (model.evaluate(padding_x, docs_class)[1]))
벡터화 할 때 0번째 단어는 비워놓기 때문에 Word_size(전체 단어의 수) + 1을 해준다. 그리고 앞에 과정에서 원 핫 인코딩은 끝났으므로 임베딩을 해준다. 벡터(클래스)는 총 8개로 구성하며, 입력의 길이는 패딩을 통해 4개 단어의 길이로 맞춰놨기 때문에 4로 설정해준다.

AI 모델링 중 지도학습에서 가장 중요한 것은 학습을 위한 데이터이다. 또한, 지도학습이 아니더라도 모델이 이해할 수 있게 데이터를 가공하고 효과적으로 제공하는 것이 중요하다. 이러한 데이터를 공유하는 사이트를 추천한다.
Kaggle: Your Home for Data Science
Kaggle: Your Machine Learning and Data Science Community
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
www.kaggle.com
'AI' 카테고리의 다른 글
| FDS(Fraud Detection System) - 이상거래탐지 (0) | 2021.02.06 |
|---|---|
| 멀티 모달(Multi Modal) 딥러닝 (0) | 2021.01.31 |
| 딥러닝(Deep Learning), 인공신경망, 퍼셉트론 (2) | 2021.01.27 |
| CNN(Convolutional Neural Network) - 합성곱 신경망 (0) | 2021.01.24 |

